About
Short BioI obtained a PhD degree in Computational Linguistics at the University of Pennsylvania under the supervision of Ellen Prince and Aravind Joshi. My research has focused on discourse structure, text analysis, pronoun resolution, and readability. My PhD work was published in top publications venues in NLP and led to the development of Antelogue, a pronoun resolution for handling pronoun resolution in dialogues. It uses discourse structure to resolve pronouns, including identification of non-referential instances of ‘it’ and ‘they’. In collaboration with Ben Taskar and his group, we proposed a novel approach for movie-script alignment that solves the correspondence problem between the visual appearance of actors in the movie and pronouns in the script. In collaboration with Rashmi Prasad and Bonnie Webber I led the development of the annotation of discourse relations of Aravind Joshi’s Penn Discourse Treebank project, the first Discourse Treebank that was based on our previous work on Discourse Parsing using basic principles from Lexicalized Tree Adjoining Grammars. During my internship with Karen Kukich at ETS I developed a novel Centering-based approach to detecting incoherent writing in student essays.
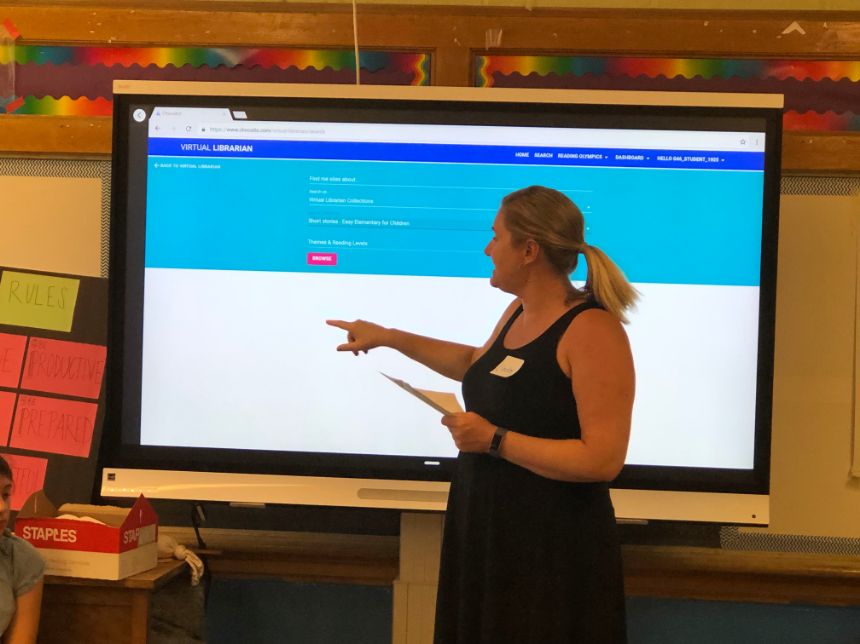
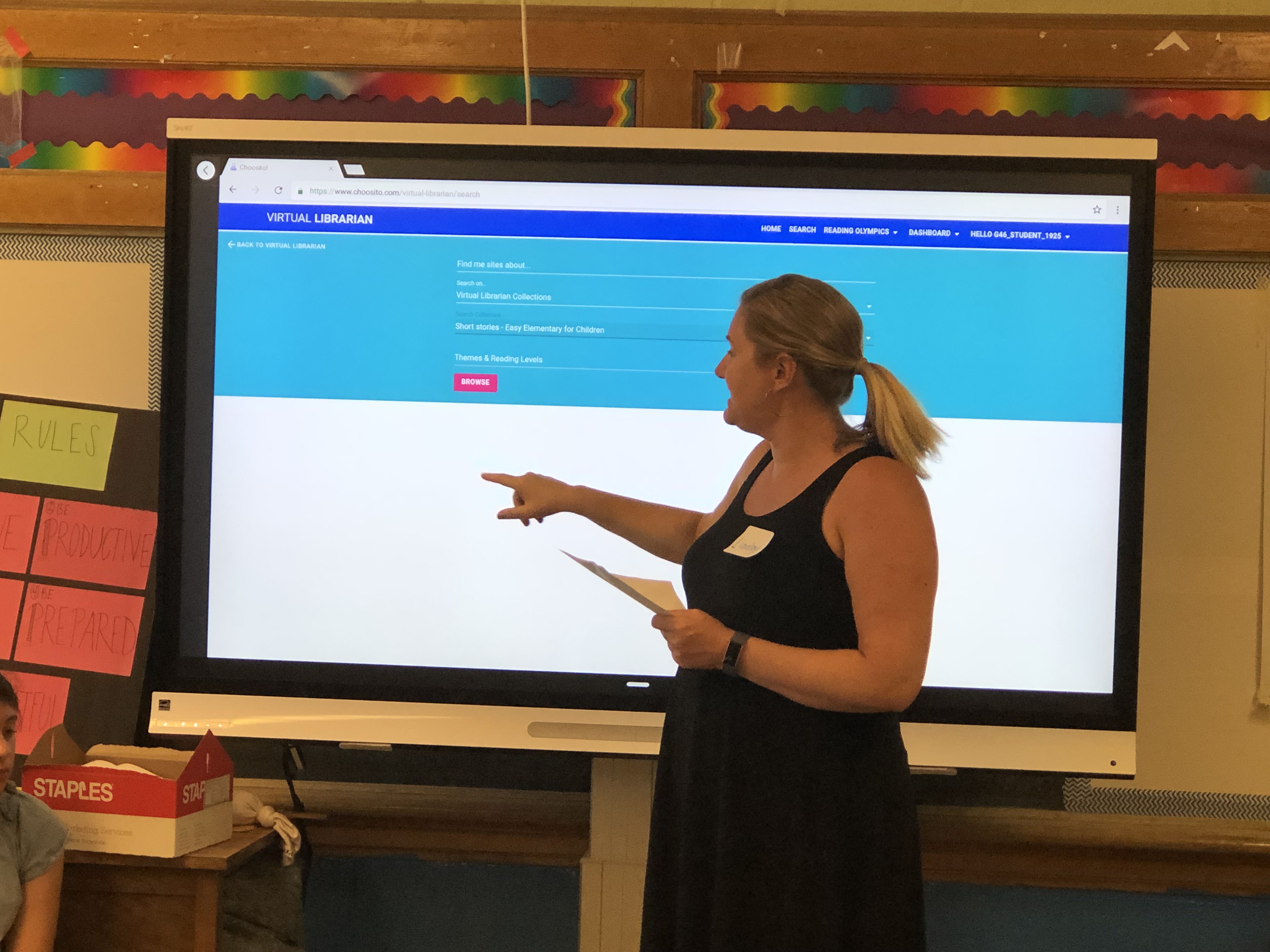
I am the founder of Choosito, an educational technology startup with a strong research record in using NLP and Machine Learning to select Open Educational Resources and other documents freely available on the web that match the reading comprehension ability and interests of the learners. With the support of two NSF grants, I have led the development and deployment of a K-12 web search engine that filters websites by reading level and theme in real-time search. With the support of a third NSF grant (in collaboration with the University of Pennsylvania) Chris Callison-Burch and our teams are currently working on the development and deployment of simplification AI for workforce upskilling and reskilling.










































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}